🏗️ The automation worked. The system hadn’t been built.
The scenario comes up often enough in conversations about legal AI that it has started to feel like a pattern. A legal team deploys an agent to handle NDA review. Six months in, by most measures it’s working: response times have dropped from days to hours, the lawyers are spending less time on first-pass reviews, the business is broadly satisfied. Then a counterparty submits an NDA with an unusual IP assignment clause, the kind that sits just outside what the playbook was built to handle. The agent reviews it, flags nothing, and sends it back. The unusual clause sails through.
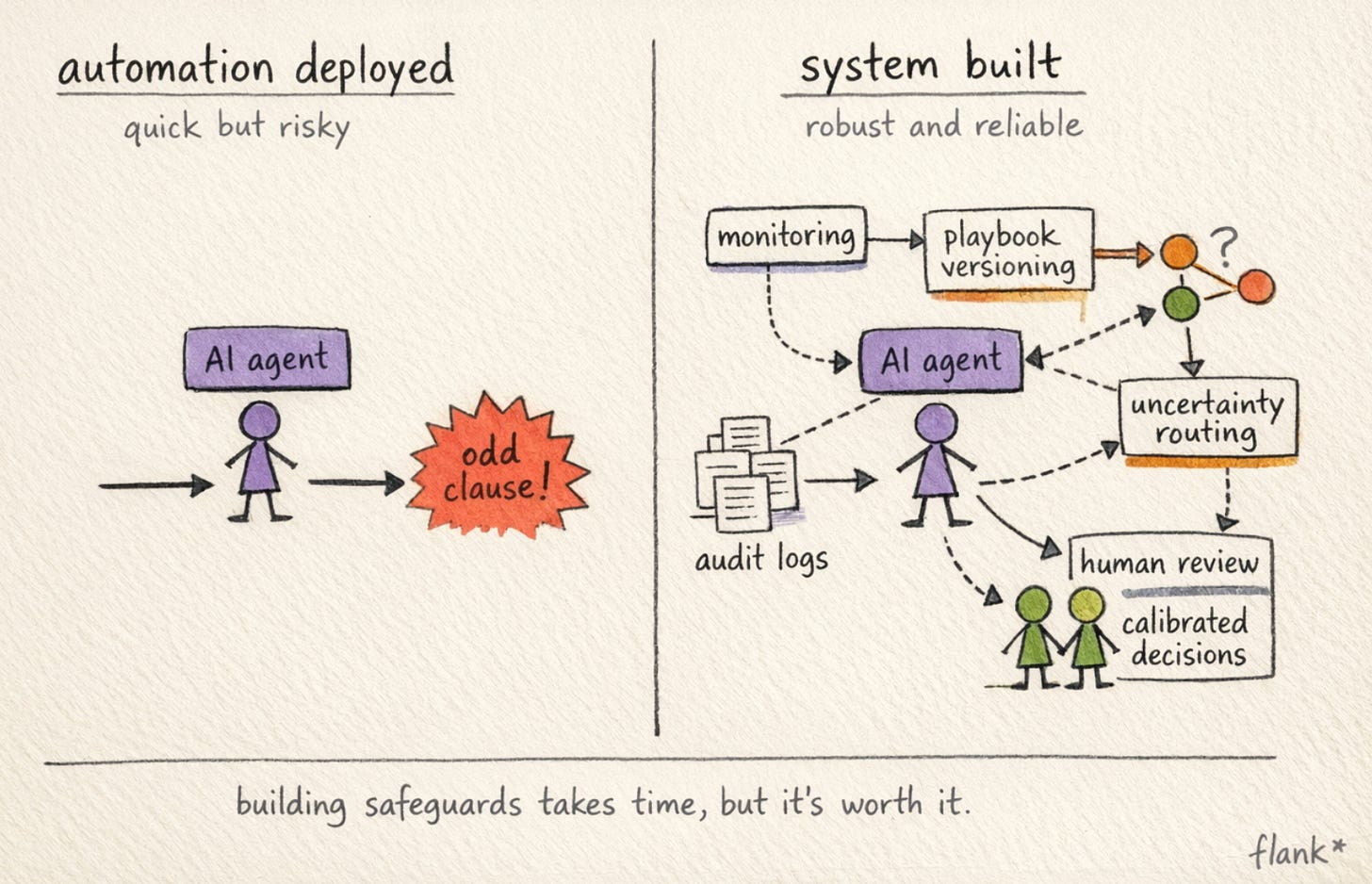
Nobody blames the agent exactly. The playbook didn’t cover the edge case. But what the team discovers, in the weeks that follow, is a harder question than “did the automation work?” It is: how do we know what the agent actually decided, and why? Can we show that to a regulator? Can we change the playbook and verify the fix works across the volume of contracts that flow through every week? And when the next edge case comes up, who in the organisation is actually responsible for it?
The automation had been deployed. The system hadn’t been built.
The 64%/7% gap
I find this pattern underneath most of the frustration I hear about legal AI right now. The 64%/7% gap that keeps surfacing in the data, where 64% of in-house teams expect their AI investments to reduce outside counsel reliance but only 7% have actually seen a reduction in total cost, is usually read as a failure of the technology. I think it is more often a failure of the surrounding system. The automation works, in the sense that the model produces reasonable output on the task it was given. But the team hasn’t built the reliability infrastructure that makes it trustworthy at volume, the defensibility layer that lets them explain and stand behind what the agent decided, or the architecture that holds together as the number of contracts doubles or triples.
64% of in-house teams expect their AI investments to reduce outside counsel reliance but only 7% have actually seen a reduction in total cost.
Picking the right task to automate is genuinely not hard. Every in-house legal team I have talked to can immediately name three or four categories of work that are repetitive, rule-governed, and high-volume. NDAs. Standard vendor agreements. Incoming triage. FAQ responses. The candidates are obvious. The question that takes longer to answer is whether the team has built a system that can carry the automation without failing in ways that are worse than the original problem.
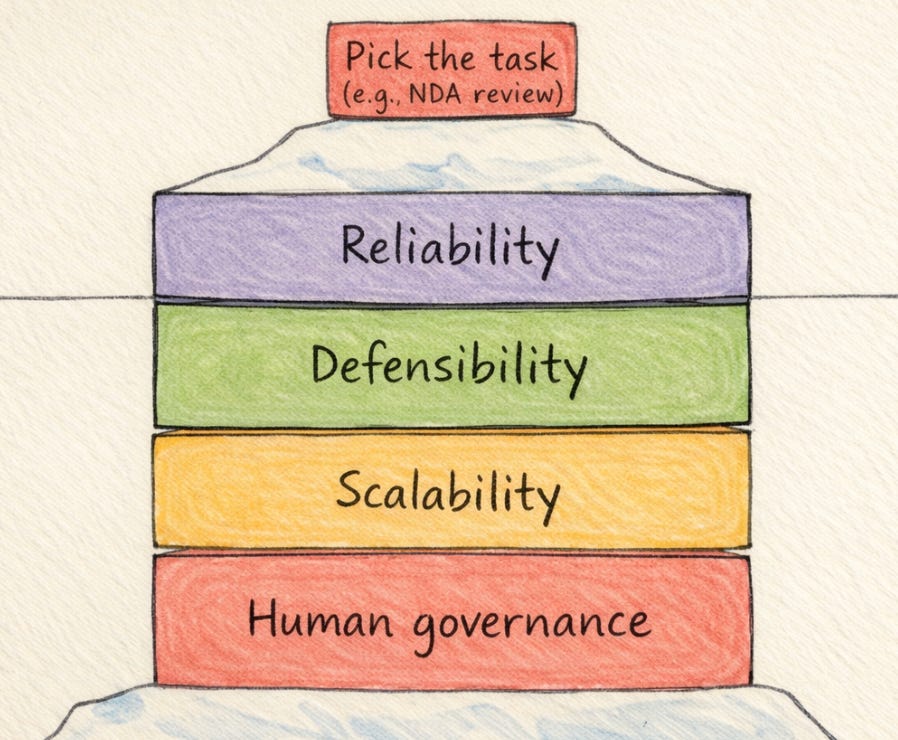
Reliability isn’t accuracy on day one
The most common way teams measure whether their automation is working is whether the agent’s output is correct, and on most contract tasks, with well-built playbooks and good models, the answer is yes, most of the time. But reliability means something harder than average accuracy on clean inputs.
Reliable legal automation has to have a designed failure mode. When the agent encounters something outside its parameters, what happens? Who is told, in what form, in what timeframe? The scenario above wasn’t a case where the agent malfunctioned. It produced output that was technically within its instructions. The failure was that the system had no mechanism to surface “I’m not sure I handled this correctly.” The agent’s uncertainty wasn’t transmitted, because nobody had designed for it to be.
This is what distinguishes a supervision model that works from one that is purely ceremonial. Teams often implement supervision, in the sense that a lawyer reviews agent outputs before they are sent, without designing for the cases where the agent should be saying something different from “here is my answer.” An agent that consistently outputs confident-sounding responses even when the underlying confidence is low, and routes all of them through the same approval flow, is not giving its supervisors the information they need to catch the edge cases. The reliability of the system depends on the quality of that signal, not just the quality of the output.
The agent’s uncertainty wasn’t transmitted, because nobody had designed for it to be.
Forrester’s finding that 25% of planned AI spend is being deferred into 2027 due to ROI concerns reflects this, I think. Teams deployed automation, discovered that maintaining it under real-world conditions required more deliberate design than anticipated, and pulled back to regroup. The technology didn’t fail. The operational model wasn’t ready for it.
Defensibility is becoming non-negotiable
The EU AI Act’s high-risk obligations land in August. Colorado’s enforcement starts in June. The ModelOp Governance Benchmark shows that AI governance platform adoption has surged from 14% to 50% of enterprises in the past year. These aren’t lagging indicators of concern. They are organisations responding to a discovered reality: AI acting in legally consequential contexts needs a traceable record of what it did and why.
Legal work is, almost by definition, legally consequential. A contract the agent reviewed and approved, a playbook position the agent applied, a redline the agent accepted or rejected: all of these can become evidence in a dispute. The question “what did the agent decide, and on what basis?” is not hypothetical. It will be asked, by a regulator or a counterparty or an internal audit team, and the system needs to be able to answer it.
The interesting thing about defensibility is that it changes the design requirements for the supervision layer. Supervision stops being about catching errors before they leave the building and becomes something broader: building an audit trail that lets the legal team stand behind the agent’s decisions even after the fact. That requires storing more than just inputs and outputs. It requires capturing which version of the playbook was active at the time, which model was used, what the agent’s reasoning looked like, and what human decisions were made at the review stage. Most teams haven’t built this yet, partly because the tools don’t make it easy, and partly because the regulatory deadline has felt far away. It doesn’t any more.
The question “what did the agent decide, and on what basis?” is not hypothetical. It will be asked, by a regulator or a counterparty or an internal audit team, and the system needs to be able to answer it.
There is also a softer version of this problem that rarely gets named explicitly, which is internal defensibility. A GC who deploys agents on routine contracting needs to be able to explain to their board, or their CFO, or a sceptical business unit leader, exactly how the system works, where human judgement sits in the loop, and what happens when something goes wrong. “The AI does it” is not an answer that builds institutional trust. “The agent applies our playbook, flags anything outside its parameters, and every output goes through legal before it reaches you” is an answer. The mechanism has to be explainable, not just functional.
Scalability is where the hidden assumptions live
A legal automation system that works for 50 contracts a month will often break, quietly and in ways that are hard to diagnose, at 500. Not because the models degrade, but because the assumptions baked into the playbook were calibrated for a specific range of inputs.
When volume is low, the unusual cases are visible. Somebody notices the IP clause. The playbook gets updated. When volume is high, the unusual cases get diluted in the aggregate. The agent handles 480 contracts correctly and 20 badly, and the bad 20 are invisible until something downstream surfaces them.
Scalability in legal automation is partly a volume question and partly a variation question. A playbook built on a sample of 50 NDAs may not have seen the full range of counterparty positions a team encounters across 5,000. As the input distribution widens, the edges of the playbook become more exposed. Designing for this means thinking about how you monitor output distribution over time, how you detect when the agent is encountering inputs it wasn’t built to handle, and how you update the playbook systematically rather than reactively.
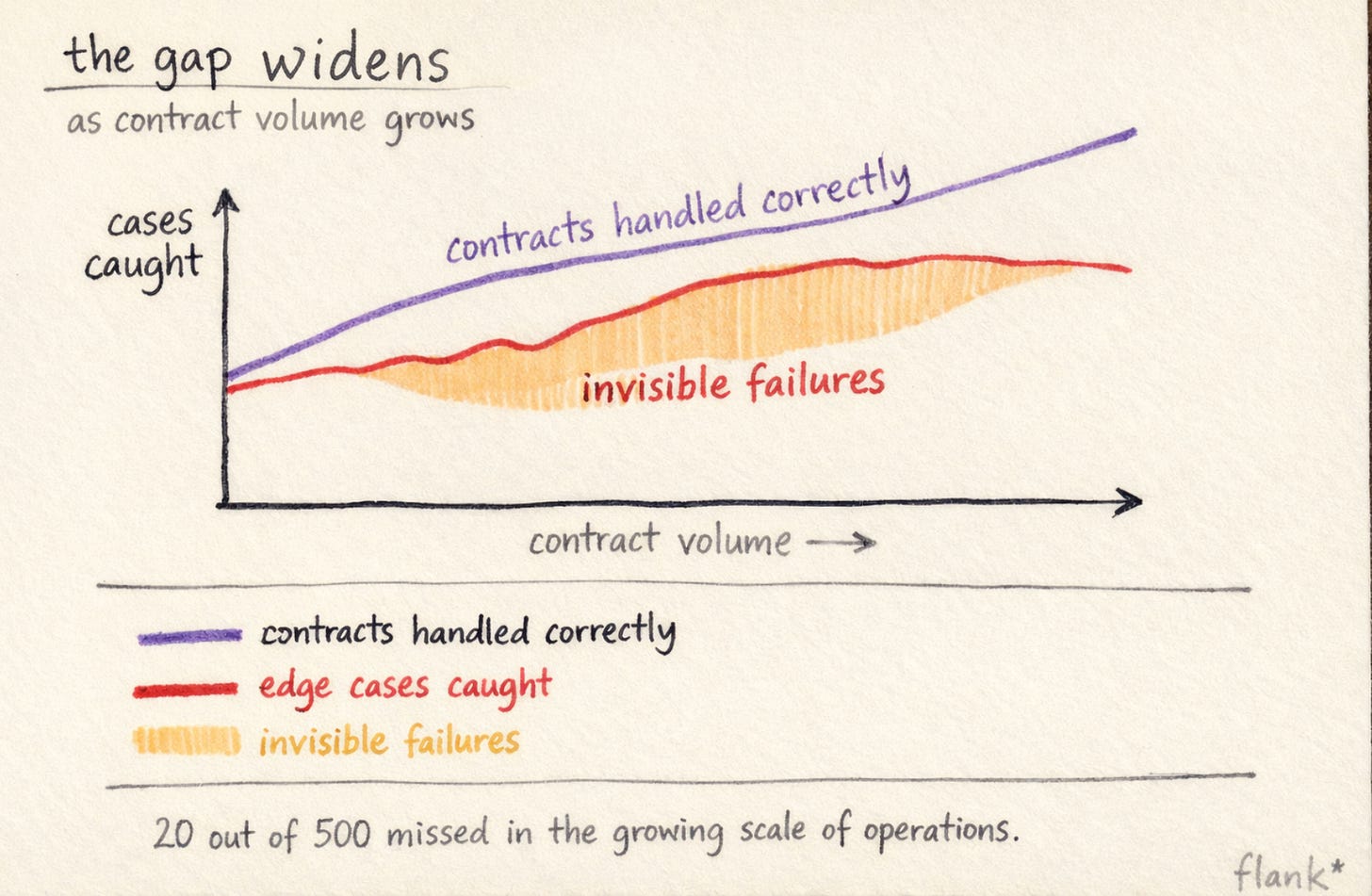
The “engine room” framing that I keep hearing from legal ops people, where agents handle the high-volume lower-judgment work while lawyers focus on the complex work that falls out, only works if there is a reliable mechanism for identifying which contracts belong in which category. That categorisation is itself a design problem. And it is one that gets significantly harder as volume grows, because the edge of “routine” is not a fixed line. It shifts as counterparty behaviour changes, as new contract types enter the workflow, as the business expands into new markets. A playbook that is static is a playbook that is degrading.
⚡The human’s role is harder, not lighter
The assumption that tends to run through automation conversations is that human involvement decreases as AI capability increases. I find this roughly correct for execution, and roughly wrong for everything else.
In a system where agents do most of the actual contract work, the human’s role shifts from executing to governing. And governance is harder than execution in almost every relevant dimension. Executing an NDA review requires legal expertise. Governing a system that reviews thousands of NDAs per month requires legal expertise, plus an ability to think statistically about output quality, plus enough understanding of how the underlying model behaves to know when its confidence should and shouldn’t be trusted, plus the operational discipline to maintain a playbook that stays current as the business evolves, plus the judgment to know when a pattern of edge cases signals a systemic gap rather than a one-off.
This is not a deskilling dynamic. It is a reskilling one, and in my experience the teams that are furthest ahead are those who have recognised it as such. Their senior lawyers are not doing less. They are doing something structurally different: designing the rules the agent operates under, monitoring the quality of its decisions at scale, and making calls that have downstream consequences for every contract the agent touches, rather than just the ones the lawyer personally reviewed. The leverage is enormous compared to individual contract review. So is the responsibility.
In a system where agents do most of the actual contract work, the human’s role shifts from executing to governing. And governance is harder than execution in almost every relevant dimension
McKinsey’s trajectory is instructive here. Their 20,000 agents, against a target of parity with their 60,000-person workforce by the end of this year, were not deployed to replace consultants doing routine work. They were deployed to absorb work the business could not have taken on with human capacity alone. The humans are still there. What they do has changed.
I think legal is on the same path, though the timeline is genuinely uncertain. Amodei tracked Claude usage at 60% augmentation and 40% automation earlier this year, with the automation share growing. But the rate of that shift depends on whether the legal teams deploying agents have done the harder systems work: the reliability design, the defensibility infrastructure, the scalability architecture, the human capability development. Without that work, the automation is real and the system is fragile. And fragile systems at scale produce failures that are worse, not better, than the manual processes they replaced.
The task was always the easy part.
✳️
📌 Further reading
A few things I have been reading that informed the thinking above, and that I think are worth your time if any of this resonated.
The Disconnect in Legal AI Is Real: All Talk, No Payoff? (Best Law Firms / Bloomberg Law) — The source for the 64%/7% gap I reference above. The full ACC/Everlaw survey of 657 in-house professionals found that while expectations for insourcing and cost reduction keep rising year-on-year, only 7% have seen actual reductions in total cost of matters, and even fewer report alternative pricing from their firms. Most respondents say it is “simply too early” for savings to materialise. I think the more honest reading is that the savings require systems work that most teams have not yet done.
Predictions 2026: AI Moves From Hype to Hard Hat Work (Forrester) — The prediction that enterprises will defer 25% of planned AI spend into 2027 is often read as a pessimistic signal. I read it as diagnostic. Forrester’s finding that only 15% of AI decision-makers reported an EBITDA lift, and fewer than a third could connect AI to financial growth, is not a technology failure. It is the gap between deploying automation and building the reliability and governance infrastructure around it, which is the central argument of this post.
The EU AI Act: The August 2026 Deadline Every Lawyer Needs to Know About (LegalAIWorld) — The most practically useful walkthrough I have found of what the high-risk obligations actually require of legal teams deploying AI. The piece makes the connection I find most important: that the audit trail is the compliance. If your system cannot produce a traceable record of what the agent decided, which playbook version was active, and what human review occurred, you are not compliant. The framing that this is also an opportunity, not just a burden, is right, and it aligns with the defensibility argument I make above.
Anthropic CEO Dario Amodei on AI, Jobs, and the 60/40 Split (CNN) — The source for the augmentation-to-automation ratio I reference. Amodei told CNN that Anthropic tracks how people use Claude and currently sees roughly 60% augmentation and 40% automation, with the automation share growing. The nuance that matters for legal is that the shift from augmentation to automation does not reduce the human role. It changes it from execution to governance, and governance at scale is harder, not easier, than the work it replaces.
Gartner Predicts Over 40% of Agentic AI Projects Will Be Cancelled by End of 2027 (Gartner) — Not legal-specific, but the closest thing to an independent validation of the argument I am making. Gartner’s three failure modes, escalating costs, unclear business value, and inadequate risk controls, map directly onto the reliability, defensibility, and scalability gaps I describe. Their finding that only about 130 of thousands of agentic AI vendors offer genuine capabilities, the rest being “agent washing,” is also worth sitting with. The technology is not the hard part. The system around it is.


