I have watched dozens of legal teams run AI pilots that “worked.” Almost none of them learned anything useful.
In my last piece I argued that the engine is not the machine — that what you build around the model matters more than the model itself. This piece is about what happens when you never build anything hard enough to break.
I’m Martin and I lead engineering at Flank.
✳️ Before you dive in: Starting next week expect to receive The Intake on Tuesdays and Thursdays.
Your AI pilots are all succeeding. That is the problem.
95% of enterprise AI pilots produce no measurable P&L impact, according to MIT’s State of AI in Business report. Most people read that as a failure of AI. I read it as a failure of ambition. The pilots that “succeed” are the ones that never attempted anything difficult enough to break.
If your legal team has deployed AI and nothing has failed, you have not tried anything worth trying. You adopted a copilot, confirmed that it makes your lawyers marginally faster at tasks they were already doing, declared success, and moved on. The staffing model did not change. The same expensive people are doing the same inexpensive work, just slightly faster. The interesting experiments, the ones that might actually change your operating model, are the ones with a real chance of not working.
To be clear about what I mean by failure. Not compliance failures. Not broken controls. Not client-impacting incidents. I mean scoped pilots that do not scale, deployment architectures that turn out to be wrong, workflow assumptions that do not survive contact with live work. The kind of failure that teaches you something you could not have learned from a vendor demo or a proof of concept on synthetic data.
The pilots that "succeed" are the ones that never attempted anything difficult enough to break.
🏗️ The J-curve is not a bug
Brynjolfsson, Rock, and Syverson published the foundational research on the productivity J-curve: when a general purpose technology arrives, measured productivity drops before it rises. The mechanism is straightforward. Organisations that adopt a genuinely new technology have to invest in what the researchers call “complementary intangibles,” new processes, new workflows, new organisational structures, new skills, before the technology produces measurable returns. Those investments are real costs. They show up as slower output, temporary confusion, and, yes, failed experiments. The MIT manufacturing study confirmed this empirically: AI adoption initially reduced productivity by an average of 1.33 percentage points. Firms that pushed through the trough outperformed non-adopters in both productivity and market share over a four-year window.
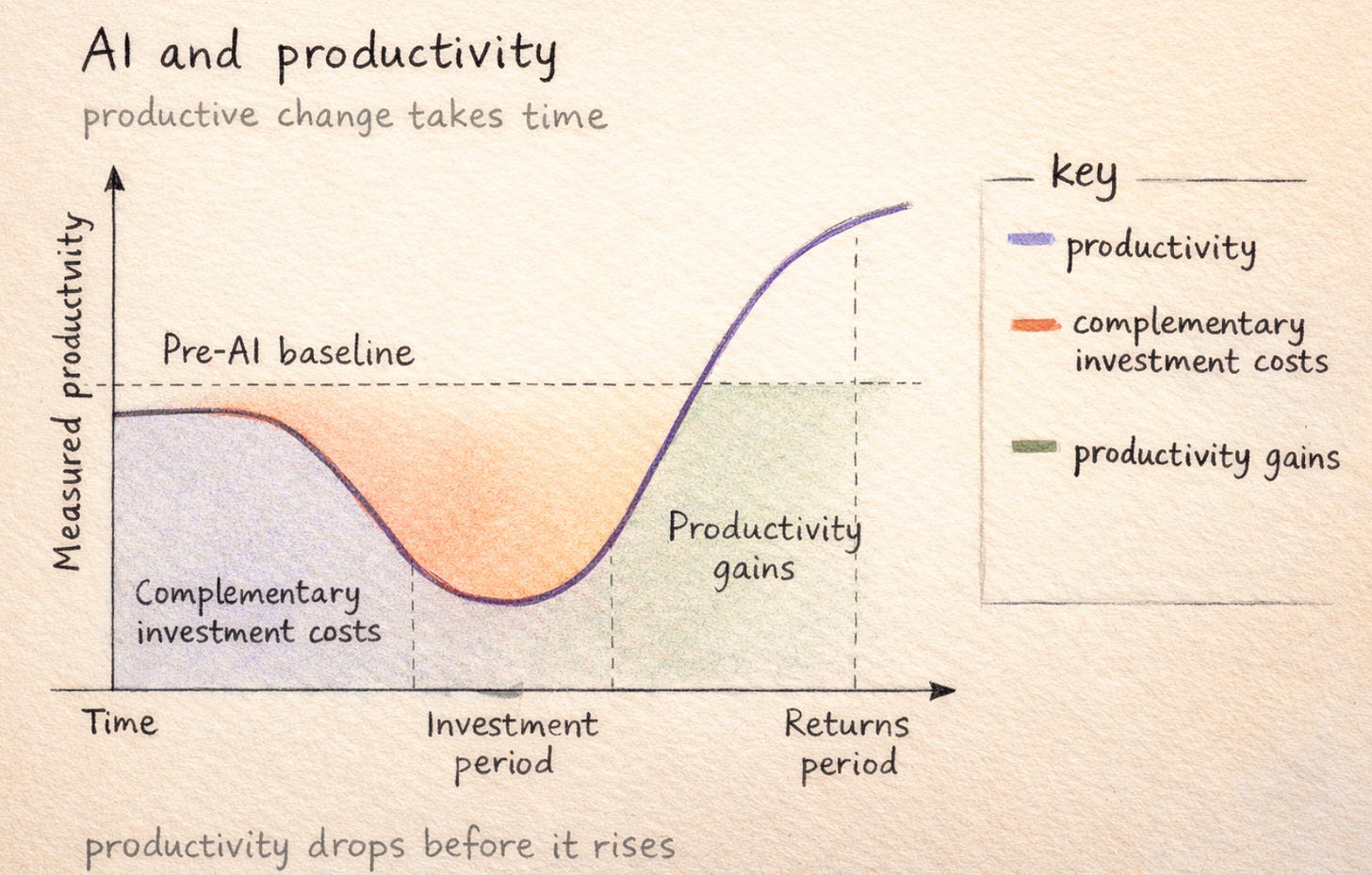
That study is about manufacturing, not legal. But the mechanism it describes, productivity dropping while organisations invest in new processes and skills before the technology pays off, is not sector-specific. It is how general purpose technologies work. The J-curve exists because learning costs something. It does not exist because the technology does not work. Legal teams that run a chatbot pilot, see no cost reduction, and conclude that AI is not ready for legal work have not disproved anything. They have confirmed that making a lawyer marginally faster is not the same as removing routine work from a lawyer’s queue, which is useful information, but only if it leads to the next experiment rather than the conclusion that experimentation is premature.
The J-curve exists because learning costs something. It does not exist because the technology does not work.
⚡ What experimentation actually costs
There is a persistent assumption that AI experimentation requires large capital allocation. It does not, at least not at the stage that matters most. The experiments that produce the highest-value learning, the ones that tell you whether agents can handle your contract triage, whether your playbook logic translates into executable rules, whether your business users will actually email a shared inbox instead of calling a lawyer, these are cheap to run. A few weeks. A handful of contract types. A defined scope with clear success criteria.
The expensive part is not the experiment. The expensive part is the organisational hesitation that delays the experiment by six months while a committee debates whether AI is “ready.” In a market where model capabilities are improving on a curve that is closer to exponential than linear, six months of waiting is not prudence. It is a compounding cost. Every month you do not run the experiment is a month of production data you do not collect, supervision patterns you do not learn, and integration problems you do not discover and solve.
The expensive part is not the experiment. The expensive part is the organisational hesitation that delays the experiment by six months.
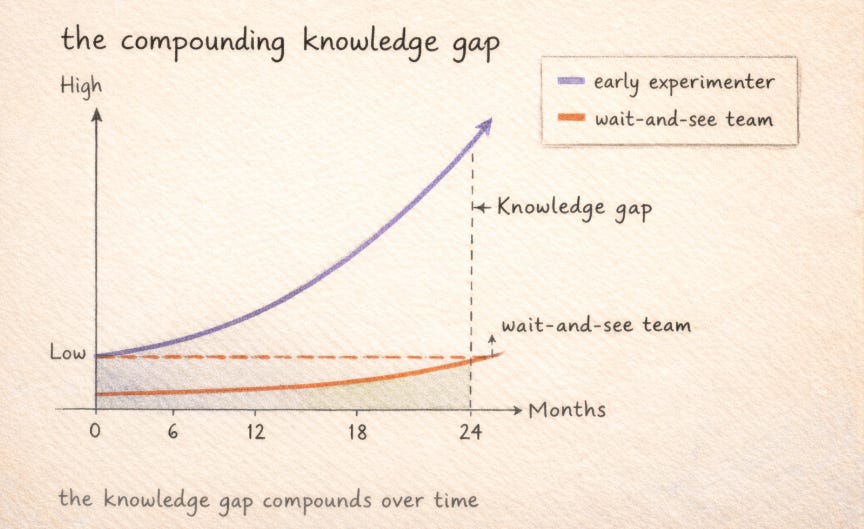
This is where the fast-follower assumption breaks down. Fast following works when the technology is stable and the question is simply when to adopt a settled tool. AI is not stable. The frontier is moving. Early deployers are not just getting earlier access to the same capability. They are building institutional knowledge that compounds: which document types the agent handles well, which escalation thresholds produce the right supervision load, which business units adopt the workflow fastest and why. That knowledge does not transfer. You cannot buy it from a vendor. You can only build it by running experiments that might not work.
The wrong unit of analysis
There is another dimension to this that complicates the “wait and see” position. Many people assume that once AI can do a task better than a human, it will immediately outcompete human labour. The economics are not that simple.
Model usage is only one line item. The real cost of running AI on legal work is the full production stack around it: integration engineering, supervision workflows, exception handling, and ongoing maintenance. For a single document, a senior lawyer reviewing an NDA at a fully loaded cost of £200 per hour may still be cheaper than routing that document through an agent with proper grounding, confidence scoring, and supervision. The economics of one document at a time do not obviously favour AI.
You cannot buy institutional knowledge from a vendor. You can only build it by running experiments that might not work.
The economics of a thousand documents a month are a different calculation entirely. At scale, the fixed costs of supervision architecture and integration are amortised across volume. The per-unit cost drops. The throughput changes structurally because the system processes work concurrently and outside office hours in ways that a human team cannot. For high-volume routine legal work, contract intake, NDA triage, standard template generation, the cost curves are crossing now.
But for many types of skilled knowledge work, humans are still cheaper. Compute costs are falling and model efficiency is improving, so the economics that hold today will not hold in eighteen months. That is precisely the argument for experimenting now rather than later. The organisations running experiments today are learning the deployment architecture, the integration patterns, and the change management while the economic pressure is still manageable. When the remaining cost curves do cross, those organisations will be ready to scale. Everyone else will be starting from scratch, in a market that has moved on.
When the remaining cost curves do cross, those organisations will be ready to scale. Everyone else will be starting from scratch.
🔒 Legal needs an R&D line item
Most legal leaders have not yet absorbed this: AI experimentation in legal requires a budget that legal departments have never had. Not a technology procurement budget. Not a headcount budget. An R&D budget. A line item specifically allocated to trying things that might not work.
This is not normal for legal. Legal departments are built around risk mitigation. The culture, the incentive structures, the career paths, all of them reward consistency and predictability. An R&D budget is the opposite. It says: we are going to spend money on experiments where we do not know the outcome in advance, because the cost of not learning is higher than the cost of the occasional failed experiment.
The amount does not have to be large. It needs to cover the cost of running structured experiments: defining a use case, configuring a deployment, running it against live work for a defined period, measuring the results, and feeding the learning into the next iteration. For most legal teams, this is a fraction of what they spend on outside counsel for routine work in a single quarter.
An R&D budget says: we are going to spend money on experiments where we do not know the outcome in advance, because the cost of not learning is higher than the cost of the occasional failed experiment.
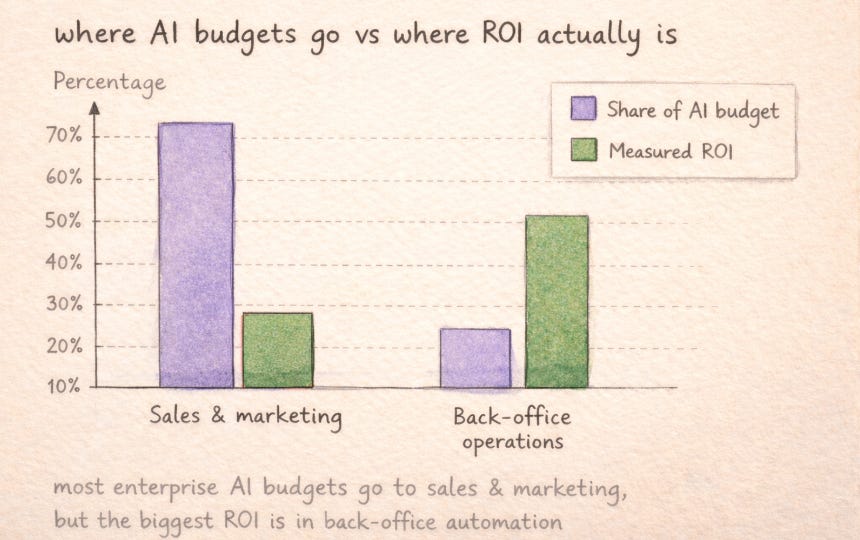
The MIT report found that the biggest AI ROI is in back-office automation, not in the sales and marketing tools that absorb the majority of enterprise AI budgets. Legal operations is back-office work. It is high-volume, rule-bound, and repetitive in exactly the ways that make it amenable to agent-based automation. But nobody will discover this by reading analyst reports. They will discover it by deploying an agent on their NDA queue and finding out what happens.
A capability to build, not a product to install
Gartner predicts that over 40% of agentic AI projects will be cancelled by end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. I read that as a description of what happens when organisations deploy agents without the complementary investments the J-curve demands: supervision architecture, organisational change management, process redesign, and the willingness to iterate through failures before reaching production-grade reliability.
The projects that will be cancelled are the ones that treated agentic AI as something you procure and switch on. The ones that survive will be the ones that budgeted for the trough, expected the early failures, and used them as learning inputs rather than evidence that the technology does not work.
The question for legal leaders is not whether AI experiments will fail. Some will. That is the mechanism by which you learn what works. The question is whether you have created the conditions, the budget, the mandate, the tolerance for productive failure, that let your team run the experiments that matter. If everything your legal team has tried with AI has succeeded, you have not tried enough. The real risk is not a failed pilot. It is arriving at the far side of the J-curve with no institutional knowledge of how to deploy the technology that your competitors have been learning to use for the past two years.
✳️
Starting next week expect to receive The Intake on Tuesdays and Thursdays.