✳️ Happy Thursday, and welcome back to The Intake.
I'm Paul. I work at Flank, where I build and deploy AI agents for enterprise legal teams.
Last week, something happened during a customer rollout that I haven't been able to stop thinking about, not because it went wrong, but because of how fast it went right again. That pattern is what this piece is about.
The failure that lasted minutes
Last Tuesday, an agent we’d deployed for a global enterprise customer hit a wall. The customer had been running Flank agents on core business contracts for weeks, performing well, handling volume, delivering work. Then they rolled out to a wider team across the organisation. And the wider team brought queries the agent hadn’t seen before. Bigger, messier, more complex requests with massive attachments that pushed against limits that hadn’t been tested in the pilot phase. A few failed. Users had to re-run their requests.
It felt terrible.
We diagnosed and fixed the issue in minutes. The agents recovered. The wider rollout continued. But that feeling, the one where something that was working confidently suddenly stumbles when it meets real-world scale, has been on my mind all week. Not because the failure was catastrophic. Because I think the pattern it represents is one of the most misunderstood dynamics in deploying AI at enterprise scale.
⚡ What the jagged edge actually looks like
The term “jagged frontier” comes from a 2023 Harvard/BCG study on AI capability. It describes the uneven boundary where AI is remarkably capable on some tasks and surprisingly brittle on others, often in ways you cannot predict until you cross the line. The original research focused on knowledge work and copilots, but I find the concept maps even more precisely onto agentic systems in production.
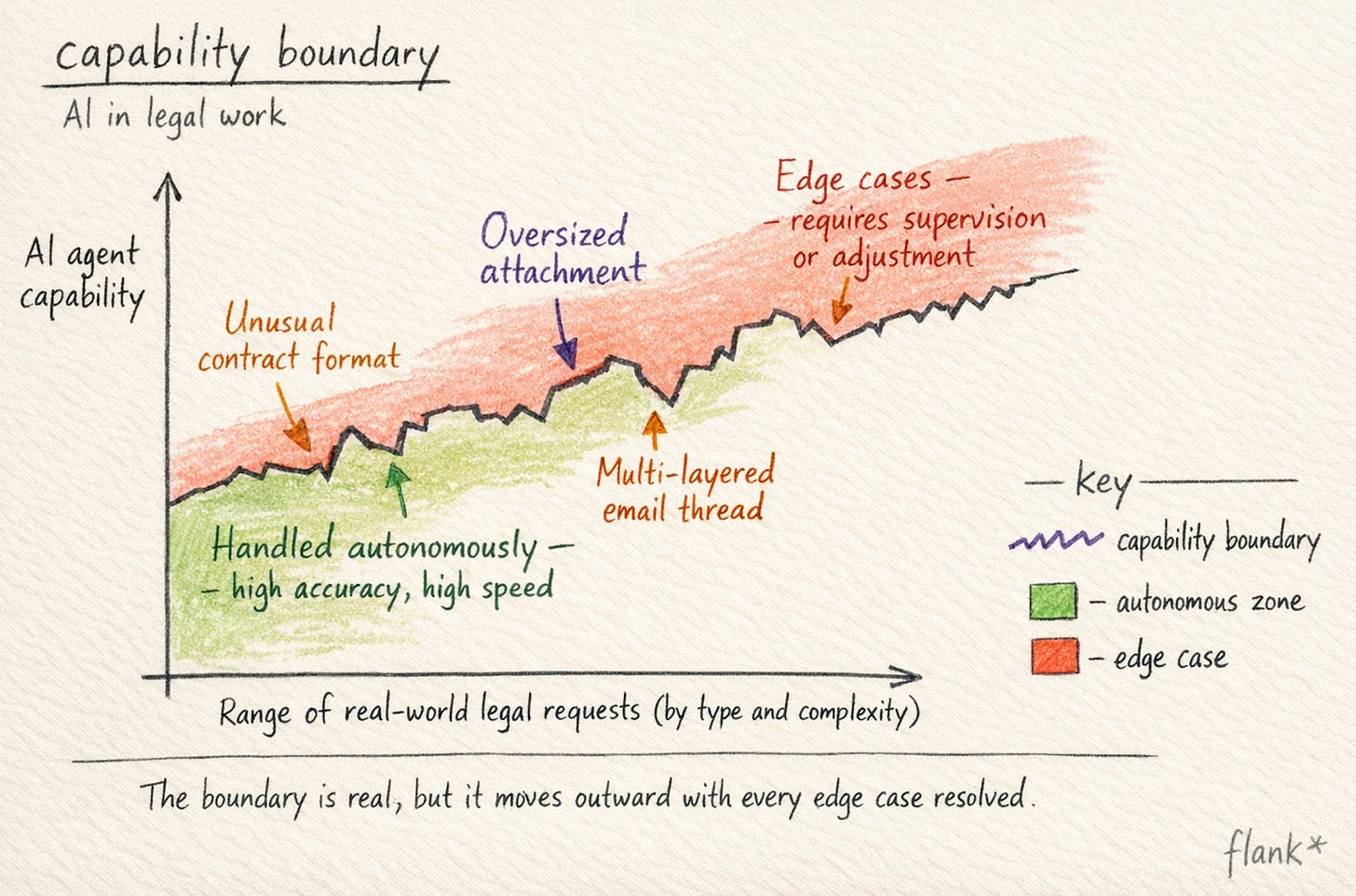
With copilots, the jagged edge is something the individual user absorbs. The lawyer pastes a clause into a chat interface, gets a strange response, adjusts their prompt, tries again. The failure surface is narrow, personal, and recoverable in the flow of work.
With agents, the jagged edge is structural. An agent that handles 200 standard NDA reviews flawlessly will, at some point, receive a request that falls outside the envelope of what it has been configured for. A counterparty template in an unusual format. A 90-page attachment that stresses document parsing. A multi-layered request that combines triage with review with a follow-up question in a single email thread. The failure is not hidden inside a single user’s workflow. It’s visible, because the agent either completes the work or it doesn’t. There is no quiet middle ground where a human can paper over the gap with judgement.
This is what happened with our customer. The pilot group had been submitting requests that fell neatly within the agent’s tested capability. The wider rollout introduced the long tail: messier inputs, larger files, edge-case combinations. The agents had been performing well enough that confidence had built quickly, and when a handful of requests failed on rollout day, the gap between expectation and outcome felt sharper than the actual problem warranted.
The failure is not hidden inside a single user’s workflow. It’s visible, because the agent either completes the work or it doesn’t. There is no quiet middle ground where a human can paper over the gap with judgement.
🏗️ The fix that matters more than the failure
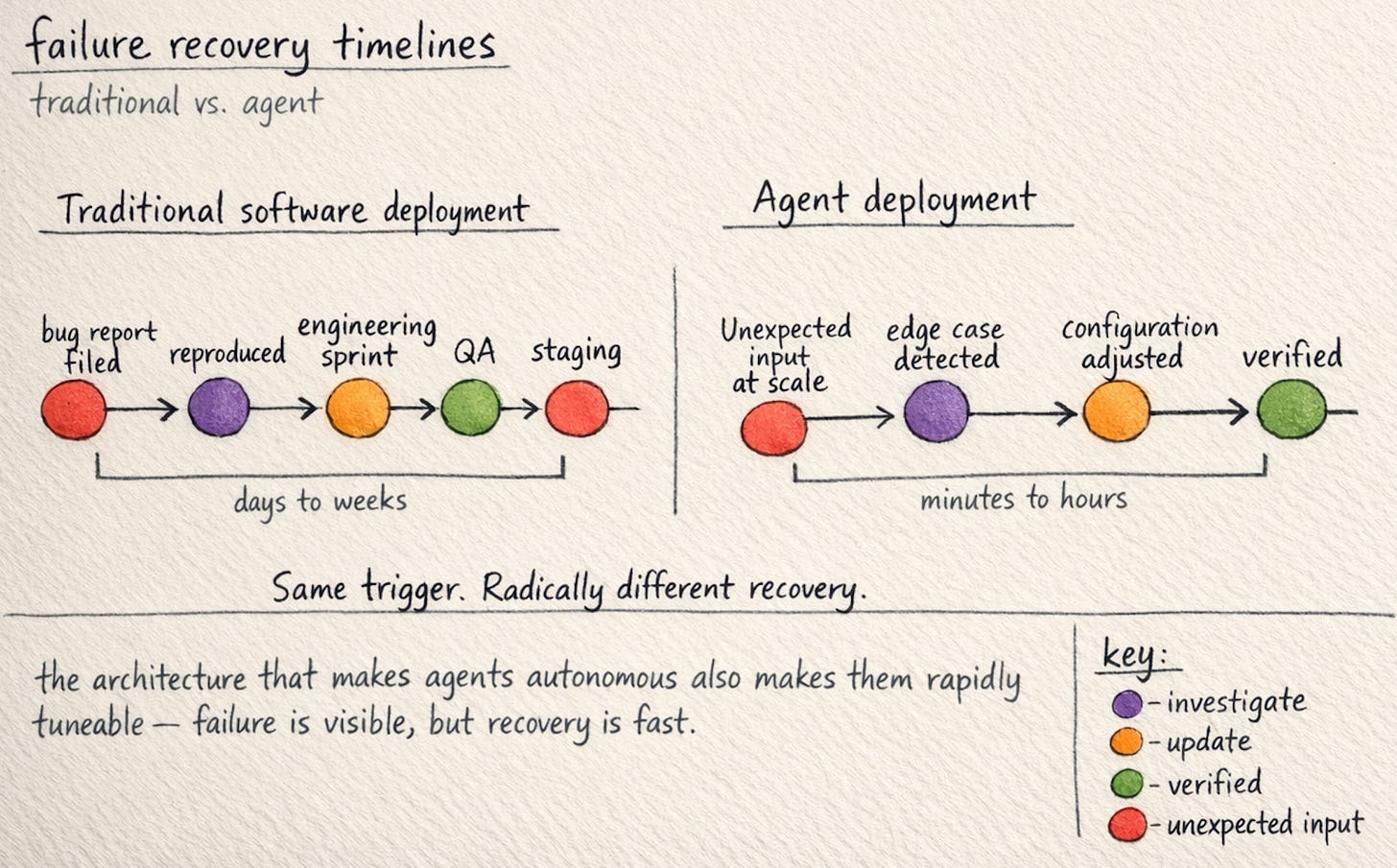
Here is the part that I think gets lost in conversations about AI reliability. The fix took minutes. Not hours. Not days. Not a re-implementation.
When a traditional software deployment hits an edge case at scale, the remediation cycle involves bug reports, reproduction, engineering sprints, QA, staging, release. Days to weeks. When an agent deployment hits an edge case, the remediation is often a configuration change, a prompt adjustment, a guardrail tweak, or a processing limit update that can be applied and verified in a single session. The system architecture that makes agents capable of autonomous execution is the same architecture that makes them rapidly tuneable when they encounter something new.
I find this asymmetry poorly understood. The failure is visible and feels alarming. The recovery is quiet and fast. And because the failure is more dramatic than the fix, the narrative tends to centre on “the AI failed” rather than “the AI was fixed in minutes and is now handling the expanded workload.”
The failure is visible and feels alarming. The recovery is quiet and fast.
This is not an argument for tolerating failures or lowering expectations. It’s an observation about the actual risk profile. If your architecture is right, meaning the agent system is modular, configurable, and observable, the jagged edge is a sharp but narrow obstacle rather than a systemic problem. You can see what went wrong, adjust the configuration, and move forward. The question is not whether you will hit the jagged edge when you scale from a pilot team to a global rollout. You will. The question is how long it takes you to recover, and what the system looks like on the other side.
Living on the edge myself
I notice this pattern in my own work, too, which is one of the reasons I wanted to write about it rather than treating it as purely a customer deployment story.
I use Claude daily, for product work, for writing, for analysis, for coding, for scheduled tasks that run overnight. It has transformed how I work. The volume and quality of output I produce in a day bears no resemblance to what was possible a year ago. And every few days, something falls over. A scheduled task fails silently. A complex query produces nonsense. A code generation run trips over itself in a way I didn’t anticipate. I re-run the query. I check the output. I adjust and try again.
This is what working at the frontier of agentic AI actually feels like. Not a smooth curve of ever-improving reliability, but a jagged, unpredictable surface where extraordinary capability and surprising fragility coexist in the same tool, sometimes in the same session. And I keep coming back to the same conclusion: the price is worth paying.
This is what working at the frontier of agentic AI actually feels like. Not a smooth curve of ever-improving reliability, but a jagged, unpredictable surface where extraordinary capability and surprising fragility coexist in the same tool, sometimes in the same session.
Not because the failures don’t matter. They do. Every failed run costs time and breaks flow. But because the capability on the other side of those failures is so substantial that the net effect is overwhelmingly positive. Where it counts, in the accuracy of contract review, the quality of drafted documents, the insight surfaced from large volumes of data, the sheer capacity multiplied across a working day, the technology is delivering.
🔒 Why the jagged edge is structural, not just a phase
I want to resist the temptation to say “it will get better” as though this is purely an early-adopter tax that will disappear with the next model release. I think the jagged edge is a structural property of agentic systems, not a temporary limitation.
Any system that operates autonomously across a wide variety of inputs will have a capability boundary that is uneven. The boundary will move outward over time, and move outward fast, but it will always be jagged rather than smooth. You cannot predict in advance exactly where a system will stumble, because the combinatorial space of real-world requests is too large to exhaustively test. This is true of human teams as well, of course. A new paralegal will handle standard work confidently and then hit a request that falls outside their experience. The difference is speed of recovery and absence of ego. The agent doesn’t need coaching or reassurance. It needs a configuration update.
The agent doesn't need coaching or reassurance. It needs a configuration update.
The implication for enterprise deployment is that planning for the jagged edge is not a sign of immaturity. It is the correct engineering posture. If your deployment plan assumes the AI will handle everything perfectly from day one across all users and all request types, you are not planning for production. You are planning for a demo. Production means supervision queues, escalation paths, monitoring dashboards, and a team that can adjust agent behaviour in real time when the inevitable edge cases arrive.
This is, incidentally, why I think the supervision model matters so much for enterprise adoption. Not because agents are unreliable, but because the jagged edge is real, and the organisation needs a mechanism to catch and correct the failures without the entire workflow grinding to a halt. The supervision inbox is what turns “a few requests failed” from a crisis into a tuning opportunity.
If your deployment plan assumes the AI will handle everything perfectly from day one across all users and all request types, you are not planning for production. You are planning for a demo.
This is as bad as it will ever be
There’s a phrase I keep returning to when I think about the current state of AI tooling. This is as bad as it will ever be.
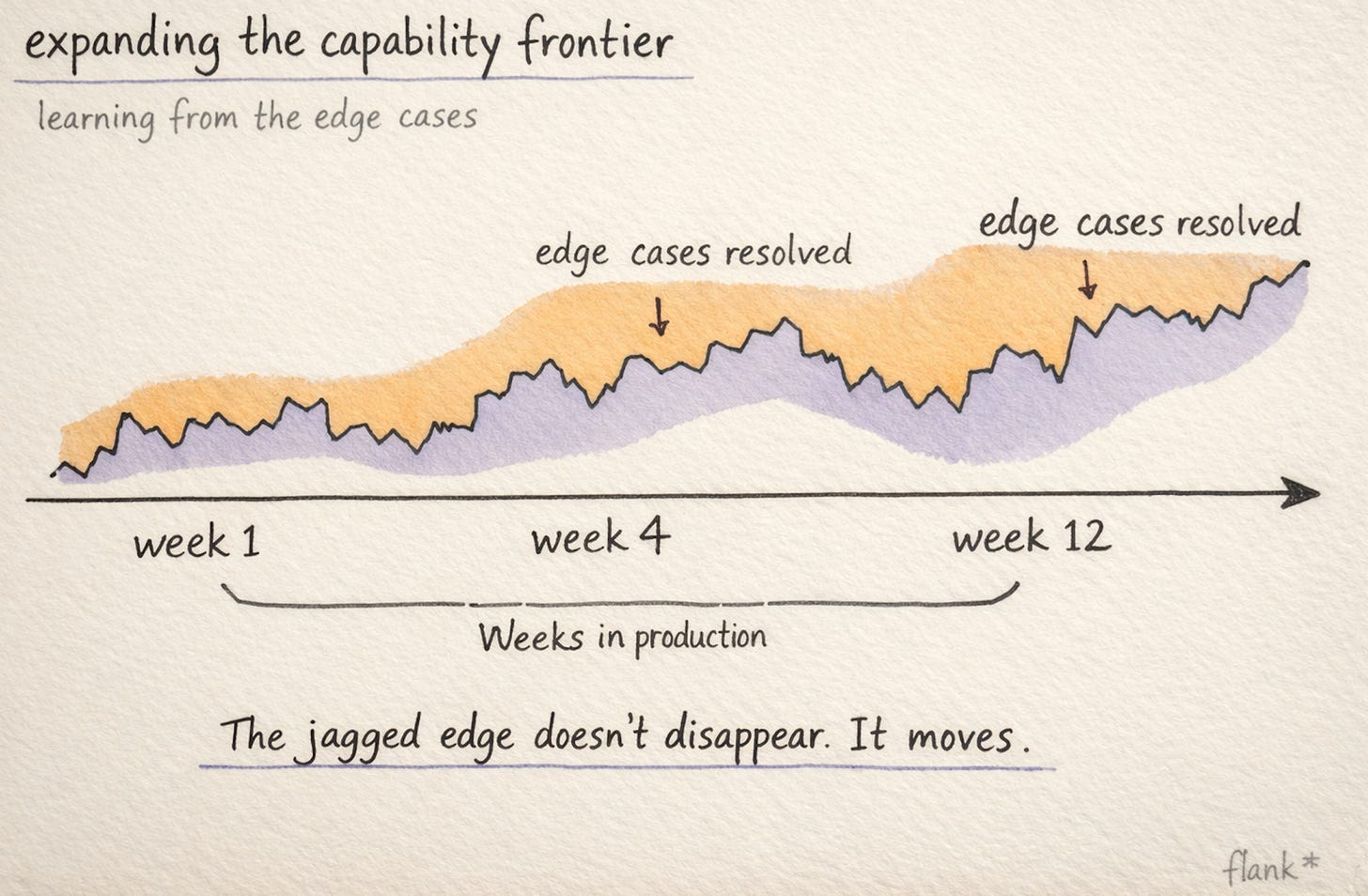
Every model release improves capability at the boundary. Every week of production data reveals and resolves another edge case. Every configuration adjustment makes the system more robust against the class of inputs that tripped it up. The jagged edge doesn’t disappear, but it moves outward. The failures you experience today are the ones that will be handled seamlessly next month.
When I re-run a failed query in my own workflow, I’m not thinking “this technology doesn’t work.” I’m thinking “this is the worst version of a tool that has already changed how I work, and it’s getting better every day.” The same applies at enterprise scale. The global customer whose agents stumbled on rollout day is now running those same agents across the wider team, handling the exact request types that caused failures, without issues. The jagged edge moved. The system learned. The deployment is better for having encountered the failure.
The supervision inbox is what turns "a few requests failed" from a crisis into a tuning opportunity.
I think the organisations that will gain the most from agentic AI over the next two years are the ones that develop a mature relationship with the jagged edge. Not ignoring it. Not using it as an excuse to wait. Deploying with appropriate supervision, building the operational muscle to respond quickly when edge cases appear, and understanding that the value delivered on the smooth side of the frontier vastly outweighs the cost of the failures at the boundary.
The jagged edge is real. And it is worth it.
✳️