Hi there,I’m Taariq and I lead the Forward Deployment team at Flank.
Last time I wrote about why AI rollouts fail on change management, not technology.
This piece is about teams that got past that, and still aren't moving the spend number. I've started calling the pattern "shadow review." Once you see it, you see it everywhere.
The lawyer who uses AI every day and still does the work by hand
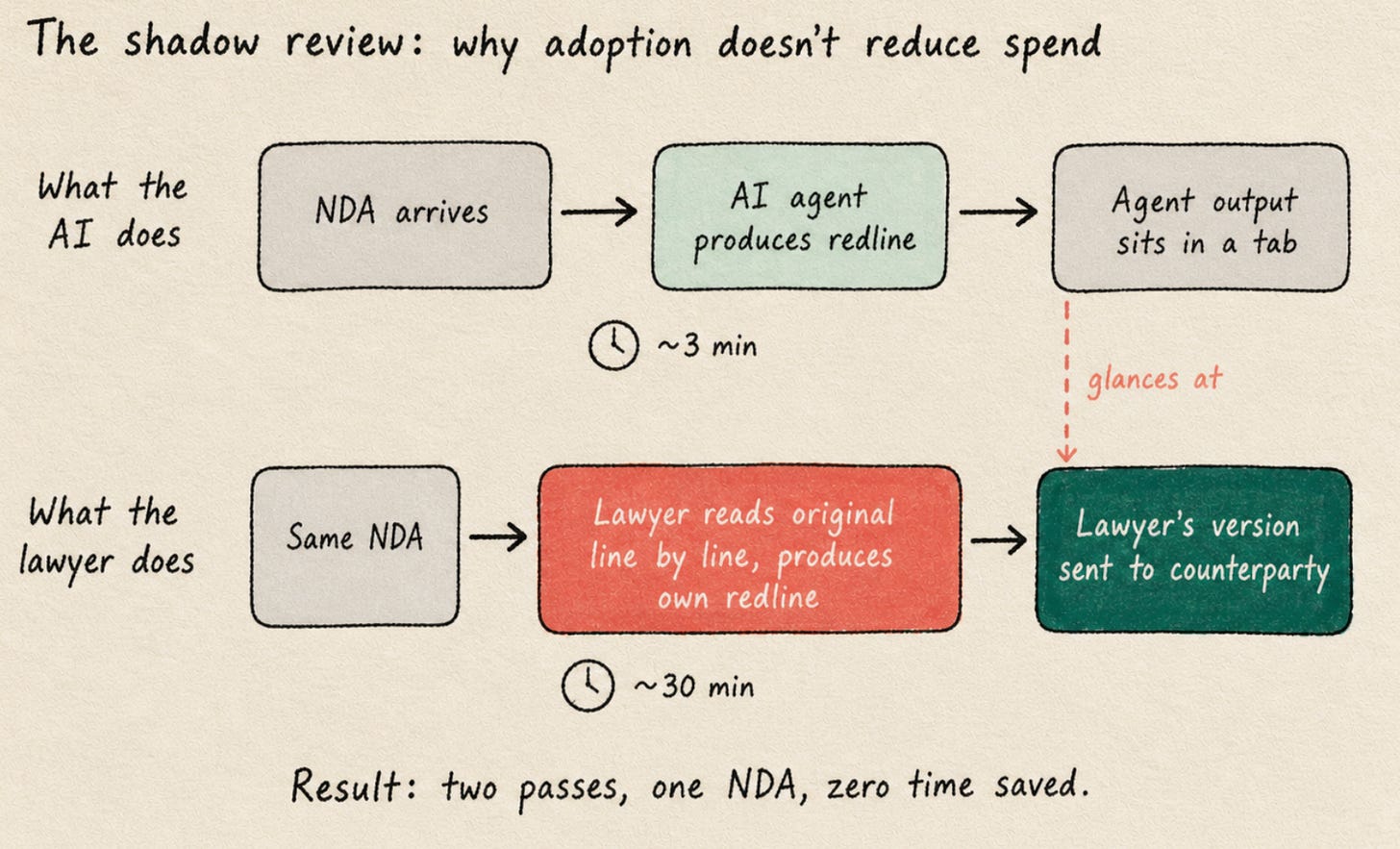
A senior associate at an in-house team I spoke with described something to me – and it makes no sense at all. She uses an AI tool for the first pass on every NDA that lands in her queue. She has done so every working day for the past six months. When I asked her how much time it had saved her, she paused. She said she still reads the original document line by line afterwards and produces her own redline by hand. The agent’s output sits in a tab she glances at while she works. Then she sends her own version.
She uses AI. She does not act on it. Both things are true at the same time, in the same workflow, on the same NDA.
I think that small contradiction is the most important pattern in legal AI right now, and it’s largely missing from how the market talks about adoption. The gap between using AI and acting on it has not closed in twelve months because of the way most teams have deployed AI. That’s the part which explains, more than anything else, why so many deployments that look successful on paper are not moving the budget.
The gap between using AI and acting on it has not closed in twelve months because of the way most teams have deployed AI.
⚡ Two numbers, same story
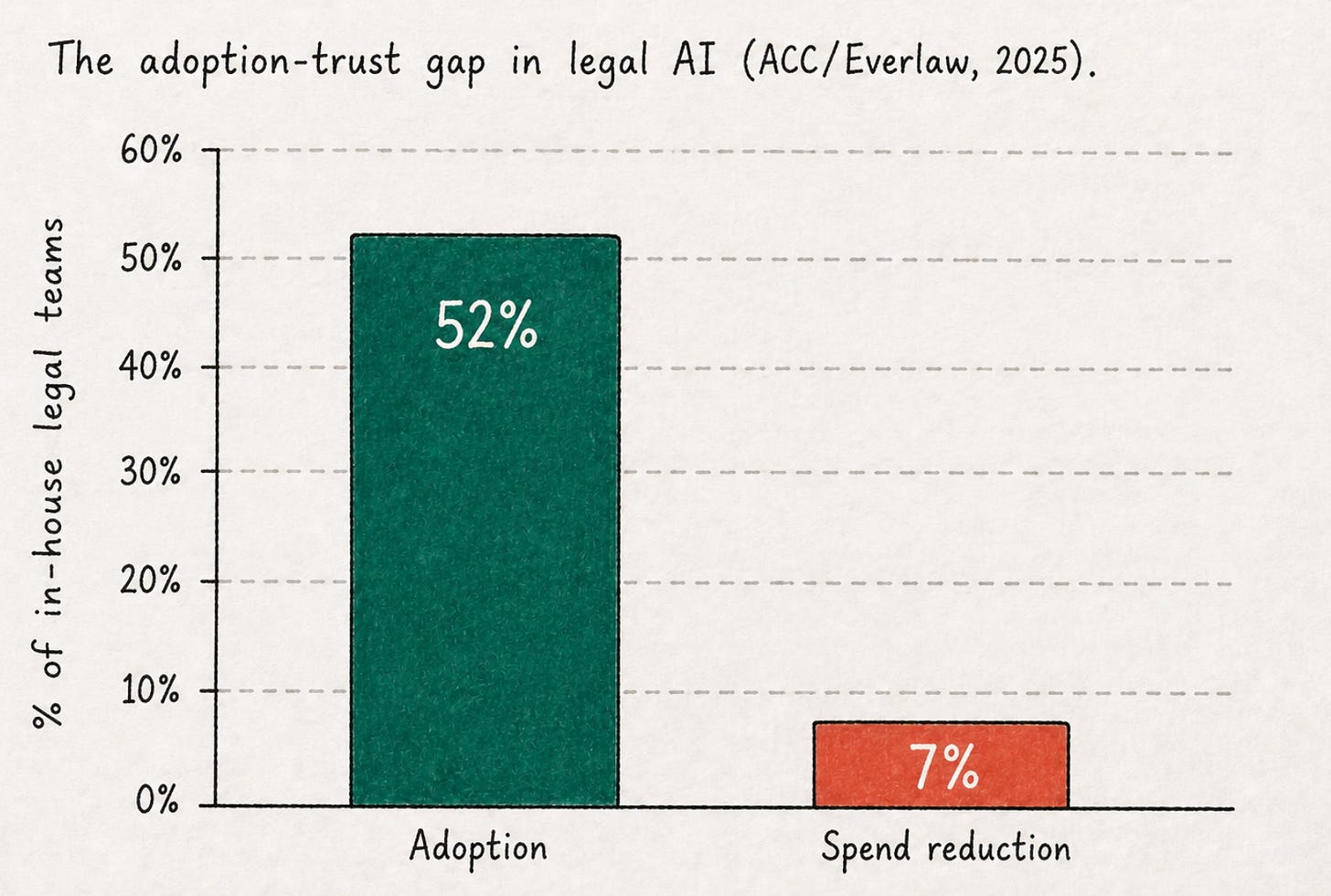
The most cited adoption figure is from the ACC/Everlaw 2025 in-house survey. Use of generative AI in corporate legal departments more than doubled in a year, from 23% to 52%. The trend has continued upwards in the year since.
The trust figure lives in the same survey, usually a few pages later. Only 7% of teams have actually seen a reduction in legal spend as a result of AI. Adoption rose by 29 points in twelve months. Spend reduction hasn’t moved.
Most of the commentary on the gap reads it as a maturity problem. The technology is new, lawyers are cautious, give it time. I find that reading incomplete. The 7% figure is not really a measurement of how lawyers feel about AI. It’s a measurement of whether anything has actually been delegated to it. As long as the deployment is built around augmenting a lawyer who is still doing the work, the spend number cannot move, because trust in this context is actually a workflow decision.
Adoption rose by 29 points in twelve months. Spend reduction hasn’t moved.
The shadow review
I’ve started calling the pattern the senior associate described a “shadow review”, because I haven’t found a better name for it and the existing labels do not quite fit. The AI produces work. The lawyer redoes it. The AI’s output gets used as a sanity check on the lawyer’s own. Then the lawyer’s work gets sent.
The lawyer used the tool. They will say so on a survey. They have a tab open in their browser that they look at every day. The deployment is, by the only measure most surveys use, working.
It has not moved any work, though. The minutes the AI tool took to produce its redline was real. The half hour the lawyer spent producing their own afterwards was also real. Net of both, the work took about as long as it always did. Sometimes it took a little longer, because the second pass was more careful than the original would have been, given the AI had primed the lawyer on what to look for.
I want to be fair to augmentation. It has a real quality lift. Magesh and colleagues at Stanford found that even with hallucination rates that should disqualify a tool from solo use, lawyers in supervised settings catch most errors. So the work the senior associate is sending is, on average, better than the work she would have sent alone. However, this was not what most legal AI budgets were authorised to deliver. The board approved the spend on the assumption that AI would change the cost structure, not the quality envelope of the existing structure. The cost structure does not change while every output is being reviewed at the document level, because the reviewing lawyer is the cost.
🔍 The diagnostic question
When I want to know whether a deployment is in the shadow-review pattern, I ask one question.
What step in your workflow stopped happening?
The wrong answer is a list of things that are now faster. Speed is what an assistant produces, and an assistant is what almost everyone has bought. The right answer names a step the team used to perform and no longer performs at all. A clause-by-clause read that is now done by a system with citations. An intake triage that no longer needs a human first read. A first-pass redline that goes to the counterparty without a lawyer rewriting it from scratch.
If no step has stopped, the deployment has added a tool to the workflow. The workflow itself has not changed. I suspect the 7% of teams that have seen real cost reduction are almost entirely the teams that can answer this question with a specific subtraction. For everyone else, AI has become a fixture of the day that has not yet earned a fixture in the budget.
What step in your workflow stopped happening?
Why this happens, mechanically
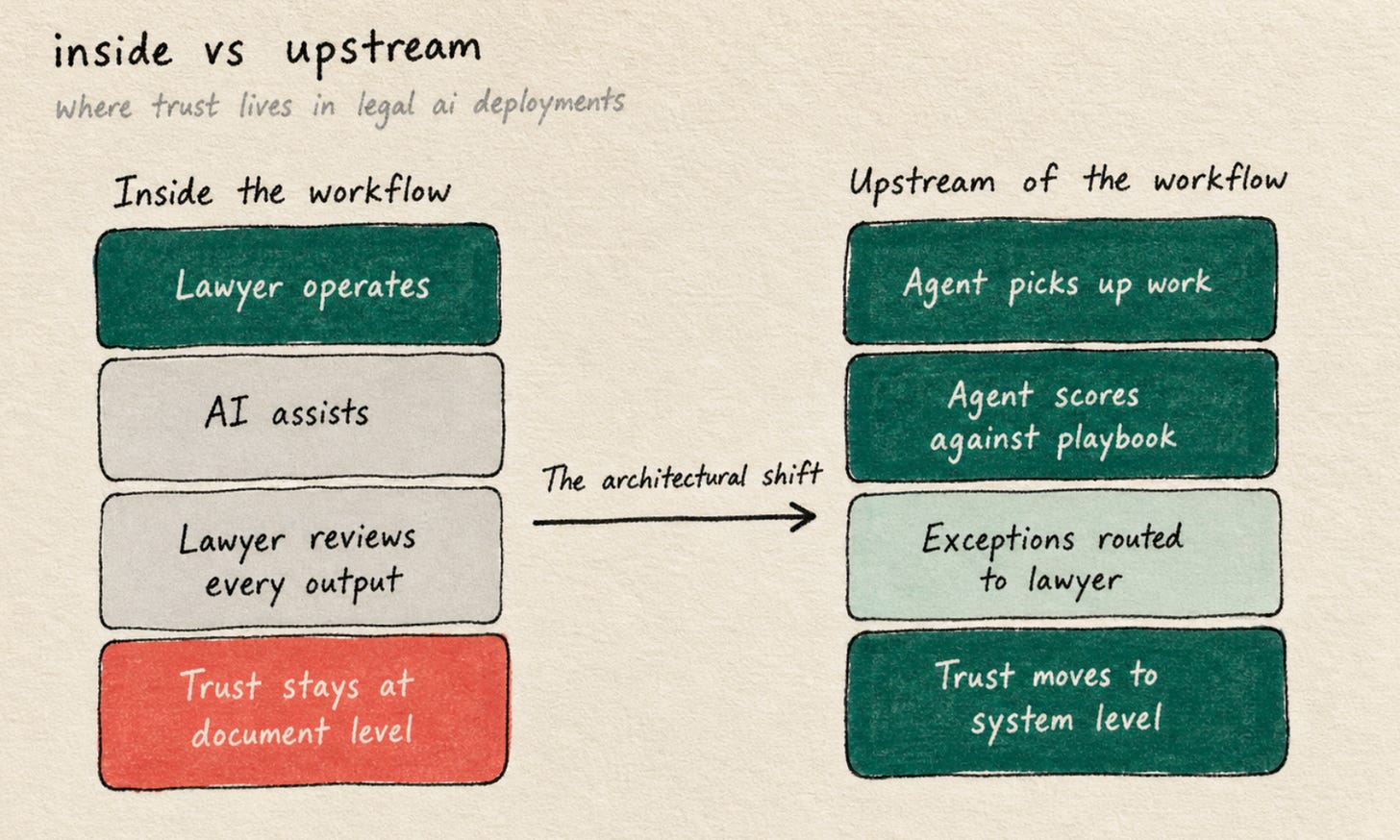
The shadow-review pattern is not a failure of will. I find that worth saying out loud, because it gets blamed on lawyers a lot, and the lawyers I work with are not the problem. The pattern is the predictable output of a deployment design that puts the agent inside the lawyer’s workflow rather than upstream of it.
Inside the workflow looks like a chat panel in the drafting tool, an assistant in the email client, a copilot in the document editor. The lawyer is still the operator. The agent is a faster keyboard. Every output passes through the lawyer’s hands, which means every output is reviewed at the document level, which means trust never moves from the document to the system. The architecture itself prevents the trust number from rising.
The architecture itself prevents the trust number from rising.
Upstream of the workflow looks different. The agent picks the work up off the queue. It runs the document against the team’s playbook. It scores its own output against the team’s risk thresholds. Outputs below the threshold are routed to a supervision queue where a lawyer reviews only the exceptions. The lawyer is no longer in the document. The lawyer is in the queue.
The numbers move the moment the architecture moves.
⚖️ What it costs to stay in the shadow
The longer a team operates in the shadow-review pattern, the more expensive it becomes, in two ways that compound.
First, the team carries the operational cost of the AI on top of the lawyer cost, rather than instead of part of it. A copilot subscription that makes a £200/hour lawyer 25% faster on a single NDA does not pay for itself, because the lawyer’s hour is still on the timesheet, just doing work that has been re-checked rather than work that was new. Every NDA that is reviewed twice is one the team paid for twice.
Second, and I think this matters more, the team is not building the institutional knowledge of the architecture that does change the cost structure. Configuring a playbook so that the tool’s confidence score genuinely tracks team risk thresholds is several weeks of work. Designing a supervision queue that the lawyers actually use, rather than route around, is more. Every month spent reviewing at the document level is a month not spent learning how to supervise at the system level.
What I am still working out
I want to be honest about what I do not know yet.
I do not know how fast the architectural shift becomes legible to the GCs and legal ops leaders who are currently celebrating the headline adoption number. The 7% spend-reduction figure is hidden a few pages into a PDF. The 52% adoption figure is on the front page. I think the gap closes when the second number starts showing up in board-level dashboards, but I haven’t yet seen many teams measure the workflow this way. They measure usage, because usage is easy to measure. The thing that matters is harder to count.
I also don’t know how cleanly the shadow-review pattern can be designed out, versus how much of it is simply a function of personal accountability that no architecture removes. A lawyer who has signed off on the wrong clause once tends to read every clause forever. The supervision queue moves their accountability up a level, from document to system, but the muscle memory takes longer to follow. The deployments I see moving fastest are the ones where someone senior on the legal team explicitly redraws the line on what each lawyer is on the hook for, and where the team has time to absorb the redraw before the volume hits. Architecture does part of the work. People do the rest, and the people part takes longer than most plans budget for.
What I am sure of is the structural point. Adoption and trust are two readings of the same workflow, and the gap between them is what your spend number is measuring. The headline adoption figure will keep climbing. It does not measure deployment success, only deployment presence. The number worth tracking, inside your own organisation, is not adoption. It is the count of workflow steps that the legal team no longer performs.
In most teams today, that count is zero. Getting it to one is the whole game.
✳️